Optimize Model
Before You Start
If you're running Optimium for the first time, please run prompt to generate template as guided below.
This will create user argument JSON file, with most of the content filled in, based on your response.
If you have already created one, you can modify it using your own text editor.
User Arguments
Step 1. Run and follow prompt
Run the following command.
import optimium
optimium.create_args_template()Follow prompts below that appears in order.
Prompt steps
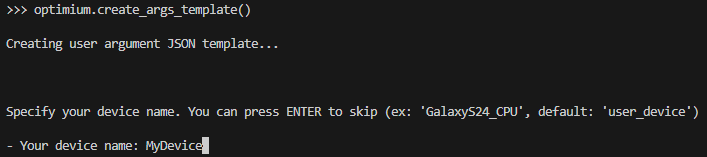
Specify device name. Once you run Optimium, the specified name will be recorded with execution history
(Optional) Specify output directory name in output. This is not mandatory.
If you leave it blank, it will be named as "outputs_{datetime}" by default.

Select framework (Type number or Name).
Optimium currently support model conversion from TF(Lite) and PyTorch

(TF Lite Only) Check if your model is post-quantized to 'float16'. Optimium currently performs inference on precision of 'float32' by default.

Check if your target device is remotely connected.

(Only if remote) Specify remote address/port. Make sure if you have launched remote server on your target device.


Select architecture of the device (type number or name). You can run command 'uname -m' in terminal of your target device (if Android, run command using adb)

Confirm if target CPU does not belong to Cortex-A(32-bit) / R / M series.

Select OS of the device (Type number or Name). For Android, SDK version will be set to '26' by default, which is the minimum support

Check 'yes' to apply all attributes supported on target device. Supported attributes, which affect performance of the generated code, vary between hardware.
It is recommended to apply all supported features for optimal performance of your model inference.
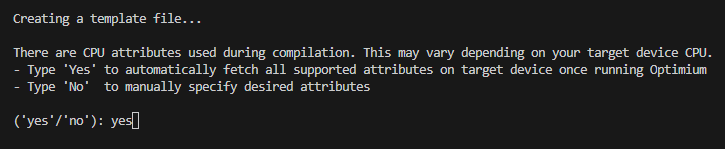
If you choose 'yes', the 'mattr' option in the result file will have its value 'auto'. We recommend not to change unless specifying certain attributes later.
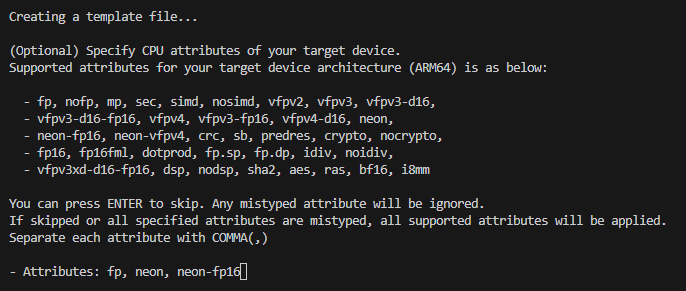
If you choose 'no', you can manually specify desired attributes.
Attributes supported in Optimium will be listed with prompt, depending on ARCHITECTURE of your target device. Among your specified list, only supported attributes will be registered.
Specify number of threads to utilize during inference. Optimium supports multi-threaded inference. However, increasing the number of threads does not always guarantee performance improvement.

Specify optimization log key. Within the same 'device name', Optimium uses this key as index and reuse execution records for later model optimization. Unless it is intended, it is RECOMMENDED to use a constant key.

Check 'yes' to proceed hardware-specific code optimization. Optimium dynamically finds out optimal code of user's model on target hardware. This may take hours depending on the model size or device power.

Congratulations! Now you have your own user argument JSON file.

Now you will see the user_arguments.json file saved in your working directory as below.
{
"license_key": null,
"device_name": "MyDevice",
"model": {
"input_shapes": [
[0, 0, 0, 0]
],
"framework": "tflite",
"tflite": {
"fp16": false,
"model_path": "YOUR_MODEL.tflite"
}
},
"target_devices": {
"host": {
"arch": "ARM64",
"os": "LINUX",
"mattr": "auto"
},
"CPU": {
"arch": "ARM64",
"platforms": [
"NATIVE"
]
}
},
"runtime": {
"num_threads": 1
},
"remote": {
"address": "192.168.0.10",
"port": 32264
},
"optimization": {
"opt_log_key": "MyOptimizationLog",
"enable_tuning": true
}
}Step 2. Fill out model information
The only remaining part is 1) exporting your model and 2) changing model information of the user arguments file created from previous steps.
Follow the instruction that varies depending on the model framework.
TF/TFLite
Export TF/TF Lite Model
Here's an example model written in TensorFlow.
import tensorflow as tf
from tensorflow.keras import layers, models
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])Convert model into TFLite format.
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()Export model to OPTIMIUM_SDK_ROOT directory.
tflite_filepath = "simple_cnn.tflite"
with open(tflite_filepath, 'wb') as f:
f.write(tflite_model)Specify TF/TFLite Model Information
From user_arguments.json file you've just created, you need to change the following part:
//user_arguments.json
{
//...
"model": {
"input_shapes": [[0, 0, 0, 0]],
"framework": "tflite",
"tflite": {
"fp16": False,
"model_path": "YOUR_MODEL.tflite"
}
}
//...
}"input_shapes": Input tensor shapes in NHWC (Channel-last) order. Specify as a 'list' of 'list'.
This is to support multiple & dynamic inputs depending on the model. If your model has a single input, just wrap with square brackets ('[]')
"input_shapes": [[1, 28, 28, 1]]"model_path": Specify model filename you just saved (DO NOT INCLUDE DIRECTORY).
"model_path": "simple_cnn.tflite"PyTorch
Prepare PyTorch Model
Here's an example model written in PyTorch.
# simple_cnn.py
import torch
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self, kernel_size):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=kernel_size, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=kernel_size, stride=1, padding=1)
self.conv3 = nn.Conv2d(64, 128, kernel_size=kernel_size, stride=1, padding=1)
self.relu = nn.ReLU()
self.flatten = nn.Flatten()
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.relu(self.conv3(x))
x = self.flatten(x)
return xIt is recommended to use layers defined intorch.nn module if available, instead of using a corresponding function defined in torch module.
Specify PyTorch Model Information
From user_arguments.json file you've just created, need to change the following part:
//user_arguments.json
{
//...
"model": {
"input_shapes": [[0, 0, 0, 0]],
"framework": "torch"
}
//...
}"input_shapes": Input tensor shapes in NCHW (Channel-first) order. Specify as a 'list' of 'list'.
This is to support multiple & dynamic inputs depending on the model. If your model has a single input, just wrap with square brackets ('[]')
"input_shapes": [[1, 1, 28, 28]]Step 3. Set working directory
Once you finished exporting and specifying your model, make sure model-related files are in your WORKING DIRECTORY. On the other hand, you can set your working directory to the location that your model files are in.
Your working directory should look like below.
TF/TF Lite

PyTorch

Launch Remote Server
Note that this step is to optimize model for your target device connected remotely.
Before running Optimium, you need to launch the remote server on your target device.
$ optimium-remote-server --port=32264Please follow the instructions in the remote server installation & launch guide and also check that OPTIMIUM_SDK_ROOT environment variable is defined.
Run Optimium!
You're now all set! Please ensure that you've followed all instructions in the installation guide.
Now run Optimium to optimize your model:
🔑License key verification
Once you run Optimium by following step below, you will be prompted to enter your license key issued from us in the earlier steps.

Save license key in your 'user_arguments.json'
To avoid manually typing license key everytime you run Optimium, please enter your license key with key "license_key" in user_arguments.json file you have created.
# user_arguments.json
{
"license_key": "AAAAA-BBBBB-CCCCC-DDDDD",
"device_name": "MyDevice",
"model": {
...
},
...
}If the key is valid, Optimium will automatically load and activate license without manual typing.
If you're trying to optimize for remote device, please make sure if remote server is running on your target device before you run Optimium.
For TFLite
import optimium
optimium.optimize_tflite_model(max_trials=64)
# def optimize_tflite_model(
# user_args_path: os.PathLike = "user_arguments.json,
# max_trials: int = None,
# )Arguments
user_args_path: os.PathLike types that indicates file name of user arguments JSON file you created. (Default: user_arguments.json). If omitted, it is assumed that the file is located where python is running. You may pass absolute path to the file.
max_trials: int types that indicates the number of performance tuning trials for each operation of model. If omitted, Optimium automatically sets to default number.
For PyTorch
import torch
import torch.nn as nn
class SimpleConv(nn.Module):
def __init__(self, kernel_size):
super(SimpleConv, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=kernel_size, stride=1, padding=1)
def forward(self, x, y):
return self.conv1(x) * y
model = SimpleConv(3)
import optimium
x = torch.rand(1,1,16,16) # your input
y = 4
optimium.optimize_pytorch_model(model, x, y=y)
# optimium.optimize_pytorch_model(
# model=model
# *model_args,
# user_args_path: os.PathLike = "user_arguments.json,
# max_trials: int = None,
# **model_kwargs
# )Arguments
model: torch.nn.Module types that indicates target PyTorch model.
user_args_path: os.PathLike types that indicates file name of user arguments JSON file you created. (Default: user_arguments.json). If omitted, it is assumed that the file is located where python is running. You may pass absolute path to the file.
max_trials: int types that indicates the number of performance tuning trials for each operation of model. If omitted, Optimium automatically sets to default number.
*model_args, **model_kwargs : submit model input argument(s) as a positional variable or keyword argument (anything you want)
Check Output Model
You can find your optimized model in the following directory, depending on user arguments.
$ ${WORKING_DIR}/outputs/{device_name}-{num_thread}-{opt_log_key}/{out_dirname}/Once optimization is done, you will see the logs like below.

Now, you can deploy this output model to your application. Refer to quickstart guide.
In any case Optimium incurs error or unintended behavior, please see Troubleshooting page.
Updated 6 months ago